
Warum die Gesundheit Ihres Ceph‑Clusters zählt
Wer virtuelle Maschinen in Proxmox auf Ceph speichert, erwartet Verfügbarkeit, Redundanz und planbare Performance. Doch Ceph ist ein verteiltes System: Eine falsche Konfiguration, ausfallende OSDs oder ein instabiles MON‑Quorum wirken sich direkt auf VMs, Container und Backups aus. Dieser Leitfaden zeigt kompakt und praxisnah, wie Sie Ihren Ceph‑Cluster systematisch prüfen, Warnsignale richtig einordnen und schnell reagieren – inklusive Kurz‑Checkliste für den täglichen Blick.
Die folgenden Beispiele setzen eine Proxmox‑Umgebung mit Ceph (RBD/CephFS) voraus. Die gezeigten Kommandos laufen typischerweise auf einem Cluster‑Node mit administrativem Zugriff.
Was „gesund“ bei Ceph bedeutet
Ceph verdichtet den Gesamtzustand in einen Health‑Status:
- HEALTH_OK: alles im grünen Bereich.
- HEALTH_WARN: Warnungen, die beachtet werden sollten (z. B. Kapazitätsgrenzen, langsame OSDs, Rebalancing).
- HEALTH_ERR: Fehler, die Redundanz/Verfügbarkeit beeinträchtigen.
Ein gesunder Ceph‑Cluster erfüllt in der Praxis:
- Health‑Status ohne Warnungen/Fehler, also idealerweise HEALTH_OK.
- Keine dauerhaften Degraded/Backfilling‑Zustände.
- MON‑Quorum stabil; alle MONs als leader/peon vertreten.
- OSDs sind „up“ und „in“. MGR ist aktiv, MDS (falls CephFS) aktiv/standby.
- Latenzen im niedrigen Millisekunden‑Bereich unter Normalbetrieb.
Die wichtigsten Basis‑Kommandos
Der schnelle Überblick:
ceph -s # oder: ceph statusTypische, aussagekräftige Teile der Ausgabe:
- health: HEALTH_OK | HEALTH_WARN | HEALTH_ERR
- services: mon (Quorum), mgr (active/standby), osd (up/in), mds (CephFS)
- data: PG‑Zahl und Zustände (z. B. active+clean)
- io: op/s (Operationen pro Sekunde), read/write‑Throughput, Latenzen
Beispielausschnitt (vereinfacht):
cluster:
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node2,node3
mgr: active: node2
osd: 12 osds: 12 up, 12 in
data:
pools: 3 pools, 512 pgs
pgs: 512 active+clean
io:
client: 150 op/s rd, 80 op/s wr; 120MB/s rd, 40MB/s wrWeitere Kernkommandos für den Tagesbetrieb:
# MON-Quorum im Detail (JSON, gut für Automatisierung/Analyse)
ceph quorum_status --format json-pretty
# OSD-Baum und Belegung (Host/OSD-Struktur, Balancing sichtbar)
ceph osd df tree
# PG-Zustände als Übersicht
ceph pg stat
# Platz- und Objektstatistik (Cluster- und Pool-Level)
ceph df
# Live-Ansicht des Clusterzustands (Events, Recovery, Warnungen)
ceph -wWorauf achten?
- op/s: sprunghafte Anstiege ohne Laständerung können Störungen signalisieren.
- Latenzen: im Normalbetrieb im ms‑Bereich; dauerhaft hohe Werte deuten auf Engpässe (Netz, OSD‑I/O, Recovery‑Druck) hin.
- recovery/backfill: darf nicht endlos laufen. Nach Hardware‑ oder Node‑Wartung ist das normal, sollte aber nachhaltig abklingen.
MON‑Quorum sicherstellen und Split‑Brain vermeiden
MONs (Monitore) bilden das Quorum – ohne stabiles Quorum ist der Cluster „blind“ für Membership‑ und Map‑Änderungen. Prüfen Sie den Status so:
ceph quorum_status --format json-pretty | jq '.monmap.mons[].name, .quorum_names'Alle MONs sollten in der Quorum‑Liste erscheinen. In der strukturierten Ausgabe stehen MON‑Rollen typischerweise als „leader“ oder „peon“. Fehlt ein MON im Quorum, prüfen Sie:
- Netzwerkpfade (Latenz, Paketverlust, VLAN/MTU‑Mismatch, Bonding/Failover).
- Zeitdienst (NTP/chrony). Abweichungen zwischen Nodes destabilisieren Cluster‑Dienste.
- Dienststatus und Logs:
journalctl -u ceph-mon@<hostname> -e.
Tritt Quorum‑Flapping auf (MONs wandern häufig aus dem Quorum), ist das ein ernstes Warnsignal. Erst Ursachen beheben, dann Dienste neu starten – nicht umgekehrt.
OSD‑Zustände verstehen: up/in ist Pflicht
Object Storage Daemons (OSDs) tragen die Daten. Zwei Zustände sind entscheidend:
- up/down: Prozess‑ und Erreichbarkeitsstatus.
- in/out: Teil der Platzierung (CRUSH) oder nicht.
„up, in“ ist der Normalzustand. Ist ein OSD „down“ (Prozess/Host gestört) oder „out“ (nicht in der Datenplatzierung), werden Replikate neu verteilt. Das sehen Sie an PG‑Zuständen wie degraded, recovering, backfilling.
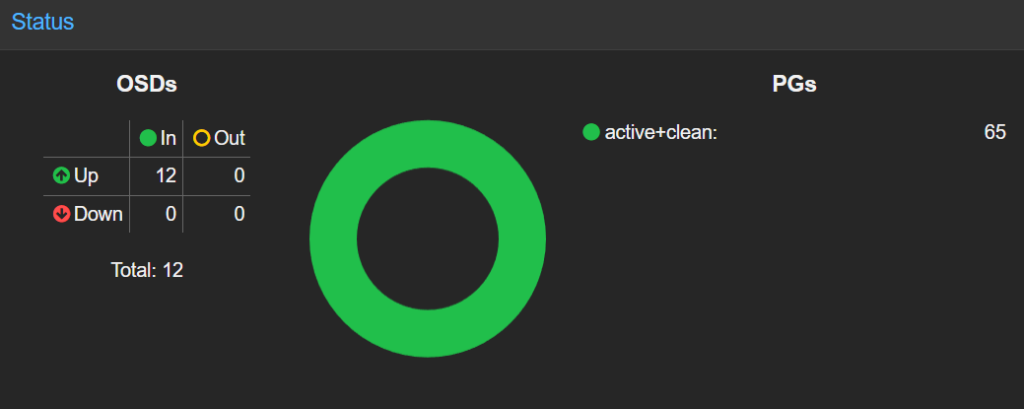
Schnelle Prüfung:
ceph osd tree # Struktur & Zustände je OSD
ceph osd df treeWenn einzelne OSDs wiederhergestellt sind, aber „out“ geblieben sind, können Sie nach Prüfung gezielt wieder aufnehmen:
# Beispiel: OSD 5 wieder in den Datenpfad aufnehmen
ceph osd in 5Bei defekten OSDs ist ein geordnetes Heraustrennen ratsam, um übermäßigen Rebalancing‑Druck zu vermeiden. Für geplante Wartung hilft das temporäre Setzen von OSD‑Flags (siehe Abschnitt „Wartung ohne böse Überraschungen“).
Placement Groups (PGs): active+clean ist das Ziel
PGs sind logische Datencontainer, die auf OSDs platziert werden. Ein gesunder Cluster zeigt überwiegend
active+cleanWeitere oft sichtbare Zustände:
degraded: mindestens eine Replik ist vorübergehend nicht vorhanden.recovering/backfilling: Daten werden neu verteilt (z. B. nach Ausfall/Ersetzung einer OSD oder nach Kapazitätsänderungen).peering: PGs handeln Zustände zwischen OSDs aus; kurze Phasen sind normal, festhängende nicht.
Lang anhaltende Nicht‑clean‑Zustände deuten auf dauerhafte Ausfälle, Netzwerkprobleme oder zu wenig freie Kapazität hin.
Kapazitäten im Blick behalten: ab 80 % wird’s kritisch
Ceph braucht freie Luft zum Atmen. Hohe Füllstände erhöhen Latenzen, verlängern Recovery‑Zeiten und können zu nearfull/full‑Zuständen führen. Halten Sie eine konservative Reserve und beobachten Sie regelmäßig:
ceph df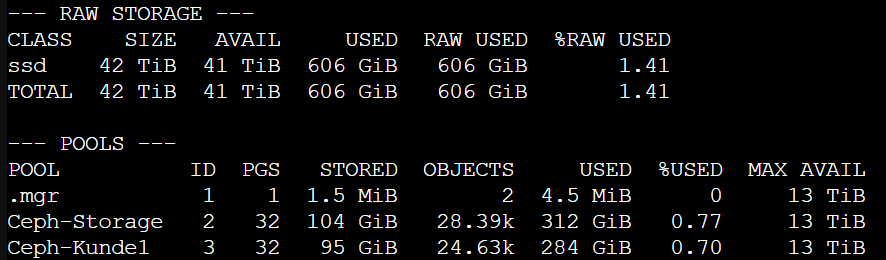
Praxisregel: Spätestens ab ~80 % belegtem Brutto‑Speicher handeln (Pool‑Layout überprüfen, Daten bereinigen, Kapazität erweitern). In Proxmox‑Umgebungen ist das besonders wichtig, wenn RBD‑Pools viele VM‑Images hosten und Backups parallel laufen.
Tipp: Lastspitzen und Backup‑Fenster korrelieren häufig. Ein belastbares Monitoring für Proxmox/Backups hilft bei der Ursachenanalyse. Wie sich Backup‑Jobs transparent überwachen lassen, zeigen wir in Proxmox Backups mit Checkmk überwachen.
Live‑Diagnose: ceph -w lesen lernen
ceph -w streamt Cluster‑Ereignisse. Achten Sie auf:
- Änderungen an osdmap/monmap (Hinzufügen/Entfernen von OSDs/MONs).
- „slow requests“ oder Meldungen über langsame/ausfallende OSDs.
- Beginn/Ende von Recovery/Backfill‑Phasen.
- Plötzliche Sprünge bei op/s und Latenzen.
Für tieferen Einblick lohnt ein externes Monitoring‑System mit historischen Daten. Ein Überblick über Werkzeuge und Erweiterungen findet sich in unserem Beitrag Effizientes IT‑Monitoring: Einblick und Erweiterungen für Checkmk.
Wartung ohne böse Überraschungen: OSD‑Flags korrekt nutzen
Bei geplanter Host‑Wartung (Kernel/BIOS/Hardware), in Proxmox etwa bei Node‑Reboots, verhindern Sie unnötiges Rebalancing:
# Während kurzer Wartung: Rebalancing vermeiden
ceph osd set noout
# Optional für heikle Eingriffe: Recovery/Rebalance pausieren
ceph osd set norecover
ceph osd set norebalance
# WICHTIG: Nach der Wartung Flags wieder entfernen
ceph osd unset norecover
ceph osd unset norebalance
ceph osd unset nooutDie Flags „noout“, „norecover“, „norebalance“ reduzieren Datenbewegungen – sinnvoll bei kurzen Eingriffen. Bleiben sie gesetzt, steigt das Risiko für Degradationszustände massiv. Dokumentieren Sie die Nutzung und setzen Sie Erinnerungen, damit Flags nicht versehentlich aktiv bleiben.
Typische Probleme und wie Sie reagieren
1) MON verliert Quorum
Symptome: HEALTH_WARN/HEALTH_ERR, no quorum, wiederkehrende leader‑Wechsel.
Vorgehen:
- Netz prüfen (Latenz, MTU, Bonding, Switch‑Logs). Kurze Paketverluste können MON‑Flapping auslösen.
- Zeitdienste prüfen (chrony/NTP). Zeitdrift destabilisiert Ceph‑Dienste.
- MON‑Logs:
journalctl -u ceph-mon@<hostname> -e. - Host‑Ressourcen (CPU/RAM/Storage) checken, v. a. wenn MON/MGR co‑located sind.
2) OSD down oder häufig „flapping“
Symptome: wiederkehrende osd.X down, PGs degraded, Recovery läuft permanent.
Vorgehen:
- Dienst prüfen:
systemctl status ceph-osd@<id>; Logs viajournalctl -u ceph-osd@<id> -e. - Datenträger/Controller testen (SMART, dmesg, I/O‑Fehler), Kabel neu stecken, Ports wechseln.
- Netzwerk zum OSD‑Host prüfen (RX/TX‑Errors, Drops, LACP‑Status, VLAN).
- Bei dauerhaften Fehlern OSD geplant ersetzen und Kapazität stabilisieren.
3) PGs bleiben in „backfill/recovering“ hängen
Symptome: ceph pg stat zeigt über Stunden unverändert backfill/recovering; Latenzen steigen.
Vorgehen:
- Freien Speicher prüfen (
ceph df), ab ~80 % kritisch. - OSD‑Hotspots erkennen (
ceph osd df tree): unbalancierte Hosts/OSDs verlangsamen Backfill. - Hintergrundlast reduzieren (Backup‑Fenster, Scrubbing‑Zeiten). Proxmox‑Backups zeitlich entzerren.
- Netzwerkfehler ausschließen; bei Bedarf Flags temporär setzen (siehe Abschnitt oben) und Root Cause beheben.
4) Latenzen dauerhaft hoch
Symptome: VM‑I/O zäh, ceph -s meldet hohe ms‑Werte.
Vorgehen:
- Parallel‑Load analysieren (Backups, Rebalance, große Restores, Reparaturjobs).
- OSD‑Hardware prüfen (NVMe/SAS, Write‑Cache, Queue‑Depth). Mögliche Engpässe identifizieren.
- Replikationsgrad/Erasure Coding und PG‑Anzahl evaluieren (Fehlkonfigurationen können Druck erhöhen).
- Netzwerkpfade und Switch‑Queues prüfen; Jumbo Frames nur einheitlich.
Proxmox und Ceph: Praxis‑Hinweise aus dem Betrieb
Proxmox VE integriert Ceph nahtlos: Pools (RBD) dienen als Datenspeicher für VMs/Container, CephFS als gemeinsam genutztes Dateisystem. Für den operativen Alltag hat sich bewährt:
- Monitoring konsolidieren: Ceph‑Metriken, Proxmox‑Clusterstatus und Backup‑Jobs zentral überwachen. Ein Einstieg in Checkmk liefert Was ist Checkmk?.
- GUI und CLI kombinieren: In Proxmox sehen Sie unter Datacenter → Ceph den Status; für tiefere Analysen nutzen Sie
ceph -s,ceph -w,ceph osd df tree. - Updates geplant durchführen: Kernel/Netzwerk‑Treiber beeinflussen Storage‑I/O. Informieren Sie sich über Neuerungen in Proxmox VE 9: Die wichtigsten Neuerungen und Änderungen und führen Sie Upgrades kontrolliert durch (siehe auch Update von Proxmox 8 auf Proxmox 9 – Tutorial).
- Backups smart timen: Hohe Backup‑Parallelität erzeugt Lastspitzen. Die oben verlinkten Beiträge helfen, Backup‑Transparenz und Alarmierung zu verbessern.
Hinweis: In Proxmox‑Umgebungen, die Ceph für produktive RBD‑Pools nutzen, zahlt sich eine konservative Auslegung (mehr OSDs, Reserven, stabiles Netz) doppelt aus. Performance‑Stabilität schlägt nominelle Maximalwerte.
„Gesundheit“ messbar machen: Checkliste für die tägliche Routine
Diese Shortlist lässt sich in 60-120 Sekunden abarbeiten. Ideal als Start‑of‑Day‑Routine oder vor Changes.
# 1) Gesamtstatus
ceph -s # Erwartet: HEALTH_OK; keine Warnungen/Fehler
# 2) OSD-Übersicht
ceph osd tree # Erwartet: alle OSDs up/in
# 3) Belegung
ceph df # Erwartet: < ~80 % belegt (Cluster & Pools)
# 4) PG-Zustände
ceph pg stat # Erwartet: active+clean
# 5) Dashboard/Alarme
# Proxmox GUI: Datacenter -> Ceph, keine roten Alarme
# Optional: Monitoring-Alarmboard (Checkmk/Icinga2) prüfenErweitert (wöchentlich/monatlich):
- Quorum‑Details und MON‑Logs querchecken (
ceph quorum_status+ Journals). - OSD‑SMART‑Werte und Kernel‑Logs (I/O‑Errors) prüfen.
- Netzwerk‑KPIs (Fehler/Drops, LACP‑Stabilität, MTU‑Konsistenz) dokumentieren.
- Kapazitätsplanung aktualisieren (Trends, Growth‑Rate, Hardware‑Roadmap).
Kapazität und Balancing lesen: ceph osd df tree richtig deuten
ceph osd df tree kombiniert zwei wichtige Perspektiven: die CRUSH‑Topologie (Nodes/Racks) und die Belegung pro OSD. Darauf achten Sie:
- Gleichmäßigkeit je Host: Starke Ausreißer bei einzelnen OSDs sind ein Indikator für Ungleichgewicht oder defekte OSDs.
- Host‑/Rack‑Redundanz: Prüfen, ob Ausfall‑Domänen wie geplant genutzt werden (z. B. Replica 3 über drei Hosts/Racks verteilt).
- Hotspots identifizieren: OSDs mit hoher Füllung und hoher I/O‑Last sind Kandidaten für gezielte Entlastung (z. B. Rebalance‑Rahmenbedingungen prüfen, Offload von besonders aktiven VMs).
PG‑„Noise“ vs. echte Störungen unterscheiden
Nicht jede recovering/backfilling‑Meldung ist ein Problem. Nach einem kontrollierten Node‑Reboot, etwa im Zuge eines Proxmox‑Kernel‑Updates, sind transiente Rebalance‑Phasen normal. Warnsignale sind:
- Backfill/Recovery läuft stundenlang ohne messbaren Fortschritt.
- Latenzen steigen dauerhaft, auch außerhalb von Backup‑Fenstern.
- Mehrere OSDs flappen oder fallen gleichzeitig aus.
In solchen Fällen ist Ursachenanalyse angesagt, nicht reines „Wegklicken“ von Warnungen.
Logs und Metriken: strukturiertes Vorgehen
Ein pragmatischer Ablauf, der sich im Betrieb bewährt hat:
- Health‑Detail auslesen:
ceph health detailgibt Hinweise mit Kontext. - Betroffene Komponenten isolieren: MON/OSD/MGR/MDS einzeln prüfen.
- Korrelationen herstellen: Zeitachsen aus
ceph -w, Monitoring‑Graphen (I/O, Latenz), Proxmox‑Events (Migration, Backup, Snapshot) übereinanderlegen. - Hypothese testen, Gegenmaßnahme dokumentieren: z. B. Flag‑Nutzung, OSD‑Tausch, Netzpfad‑Fix.
Für ein robustes Alarmierungs‑ und Metrik‑Set bietet sich Checkmk an – von der schnellen Grundierung bis zur tiefen Integration zeigen wir konkrete Vorgehensweisen in Effizientes IT‑Monitoring: Einblick und Erweiterungen für Checkmk.
Sicherheitsnetz für den Alltag: sinnvolle Betriebsregeln
- Keine Schnellschüsse im Produktivsystem. Erst Ursache verstehen, dann Maßnahmen ergreifen.
- Flags wie
nooutnur mit Timer/Change‑Dokumentation setzen und zuverlässig entfernen. - Updates (Proxmox/Ceph/Kernel/NIC‑Firmware) fensterbasiert, mit Rollback‑Plan.
- Backups kapazitiv und zeitlich planen; RBD‑Pools nicht „auf Kante“ fahren.
- Dokumentation aktuell halten (Topologie, OSD‑IDs/Disks, Netzdesign, MTUs, VLANs, Bondings).
Beispiel: Geplanter Reboot eines Proxmox‑Nodes mit Ceph‑OSDs
Ziel: Reboot ohne unnötiges Rebalancing und ohne Risiko für Daten.
1) Vorbereitung
- Kurzlastphase wählen (außerhalb Backup/Reports).
- Monitoring im Blick,
ceph -smuss sauber sein. - Optional Flags setzen:
ceph osd set noout2) Reboot des betroffenen Nodes
- Geordnet stoppen, BIOS/Firmware‑Update durchführen, System starten.
- Prüfen, dass alle OSD‑Dienste wieder „up“ sind (
ceph osd tree).
3) Validierung
ceph -sundceph pg statkontrollieren.ceph -wfür 2-5 Minuten beobachten (ungewöhnliche Events?).
4) Aufräumen
ceph osd unset noout5) Nachbereitung
- Monitoring‑Events und Ceph‑Logs kurz prüfen.
- Change dokumentieren.
Erweiterung: Monitoring sauber aufsetzen und verzahnen
Ein integriertes Monitoring bringt Ruhe in den Betrieb. Für Proxmox‑ und Ceph‑Umgebungen hat sich ein Ansatz bewährt, der Cluster‑Storage, Hypervisor und Backups zusammenführt. Ideen und Best Practices dazu finden Sie neben den bereits genannten Beiträgen auch in unserem Überblick Was ist Checkmk?. Für Proxmox‑Spezifika lohnt zudem ein Blick auf aktuelle Plattform‑Neuerungen in Proxmox VE 9: Die wichtigsten Neuerungen und Änderungen.
Kurze, praxistaugliche Routine‑Checkliste
ceph -s→ HEALTH_OK?ceph osd tree→ alle OSDs up/in?ceph df→ < ~80 % belegt?ceph pg stat→ überwiegend active+clean?- Proxmox‑Dashboard → keine roten Alarme?
Mit dieser Routine fangen Sie 90 % der typischen Probleme früh ab und haben genug Vorwarnzeit, um strukturiert zu reagieren.
Wenn Sie Ceph in Proxmox produktiv betreiben und eine belastbare Betriebsroutine aufbauen möchten, begleiten wir Sie gerne – von Design und Implementierung bis hin zu Monitoring und Notfall‑Prozessen. Mehr zu unseren Proxmox‑Leistungen finden Sie auf der Seite ADMIN INTELLIGENCE – Proxmox Services. Für Monitoring‑Setups mit Checkmk beraten wir ebenfalls praxisnah. Stöbern Sie für weitere Praxistipps in unserem Blog unter https://blog.admin-intelligence.de/ oder schreiben Sie uns direkt über https://www.admin-intelligence.de/kontakt/ – wir unterstützen Sie gern beim nächsten Schritt.