
In der Welt der künstlichen Intelligenz sind LLMs (Large Language Models) wie GPT, BERT und Co. die Stars. Aber was, wenn du ein solches Modell lokal auf deinem eigenen Server ausführen möchtest? Ollama ist eine großartige Möglichkeit, dies zu tun. Es ermöglicht dir, verschiedene leistungsstarke Sprachmodelle direkt auf deinem Server zu laden und zu verwenden – ohne dich um die Infrastruktur kümmern zu müssen.
In diesem Artikel zeige ich dir, wie du Ollama installieren, die Web-UI einrichtest und mit verschiedenen Modellen experimentierst. Ob du mit vortrainierten Modellen arbeiten möchtest oder eigene Modelle ausprobieren willst – hier findest du eine detaillierte Anleitung, um das Beste aus Ollama herauszuholen.
Inhaltsverzeichnis
- Einleitung: Was ist Ollama?
- Voraussetzungen für die Ollama-Installation
- Schritt 1: Ollama auf deinem Server installieren
- Schritt 2: Modelle herunterladen und verwenden
- Schritt 3: Web-UI einrichten (inkl. GPU-Support)
- Schritt 4: Mit den Modellen interagieren
- Fazit zur Ollama-Installation & Web-UI
Was ist Ollama?
Bevor wir einsteigen, ein kurzer Blick auf Ollama: Es handelt sich um eine benutzerfreundliche Lösung, um leistungsstarke Sprachmodelle direkt auf deinem eigenen Server auszuführen. Ollama stellt sicher, dass du keine komplexen Modelle von Grund auf neu trainieren musst, sondern einfach vortrainierte Modelle herunterladen und verwenden kannst.
Die Web-UI von Ollama bietet eine einfache Benutzeroberfläche, mit der du in Echtzeit mit den Modellen interagieren kannst. Damit ist es eine ausgezeichnete Wahl für Entwickler, die ein einfaches Setup ohne viel Aufwand suchen.
Voraussetzungen: Was du für die Ollama Installation und Web-UI brauchst
- Server oder lokales System mit Ubuntu oder einem anderen Linux-basierten Betriebssystem.
- Docker für die Installation von Ollama (wird benötigt, um die Modelle als Container auszuführen).
- Git zum Herunterladen der Web-UI.
- Node.js für das Starten der Web-Oberfläche.
Schritt 1: Ollama auf deinem Server installieren
Ollama nutzt Docker, um die Modelle zu isolieren und einfach auszuführen. Das bedeutet, du musst zunächst Docker auf deinem System installieren, falls es noch nicht installiert ist. Folge diesen Schritten:
1.1. Docker installieren
Führe die folgenden Befehle aus, um Docker zu installieren und zu starten:
sudo apt update
sudo apt install -y docker.io
sudo systemctl enable --now dockerÜberprüfe, ob Docker korrekt installiert wurde:
docker --version1.2. Ollama Docker-Image herunterladen
Jetzt kannst du das Ollama Docker-Image herunterladen. Ollama stellt eine Vielzahl von Modellen bereit, die du nach Belieben nutzen kannst. Zum Herunterladen des Images führst du einfach diesen Befehl aus:
docker pull ollama/ollama:latest1.3. Ollama-Container starten
Nachdem das Docker-Image heruntergeladen wurde, starte den Container:
docker run -d -p 5000:5000 ollama/ollama:latestDer Ollama-Container läuft jetzt auf deinem Server und ist unter http://localhost:5000 erreichbar.
Schritt 2: Verschiedene Modelle herunterladen und verwenden
Ollama unterstützt viele vortrainierte Modelle, die du einfach herunterladen und verwenden kannst. Doch wie wählst du das richtige Modell aus und lädst es herunter?
2.1. Modelle herunterladen
Ollama bietet eine einfache Möglichkeit, Modelle direkt über die Kommandozeile herunterzuladen. Um ein Modell herunterzuladen, kannst du den folgenden Befehl verwenden:
docker exec -it <container_id> ollama pull <modellname>Zum Beispiel, um das LLama-3.3 Modell herunterzuladen:
docker exec -it <container_id> ollama pull llama3.3
docker exec -it <container_id> ollama run llama3.3
#oder in den container gehen und dann
ollama pull llama3.3
ollama run llama3.3Um dein Modell auszuwählen gehst du auf die offizielle Ollama Seite und suchst dein Modell. Dann kopierst die den Command raus und setzt in in deinen Befehl ein. Durch den Run Befehl kannst du mit dem Modell auf dem Terminal interagieren.
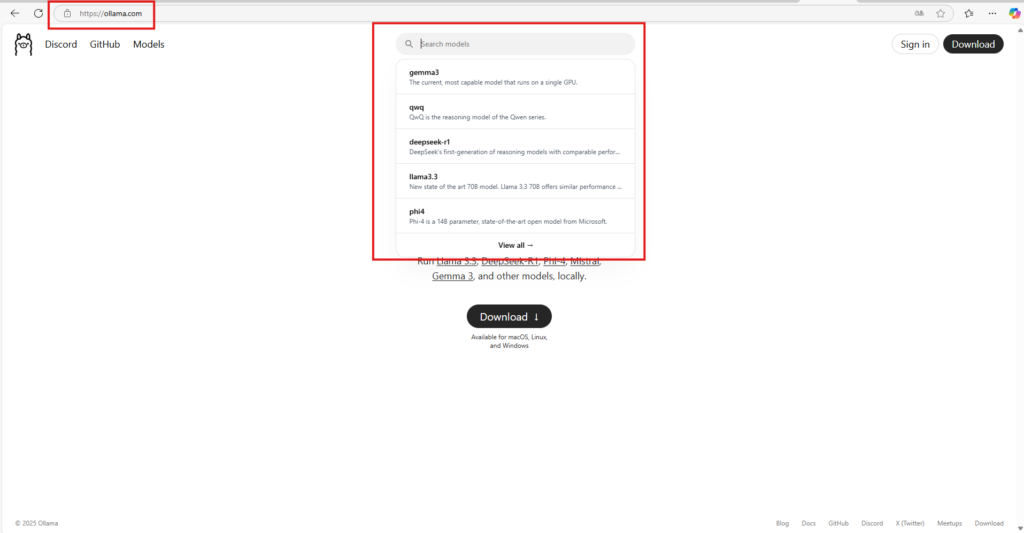
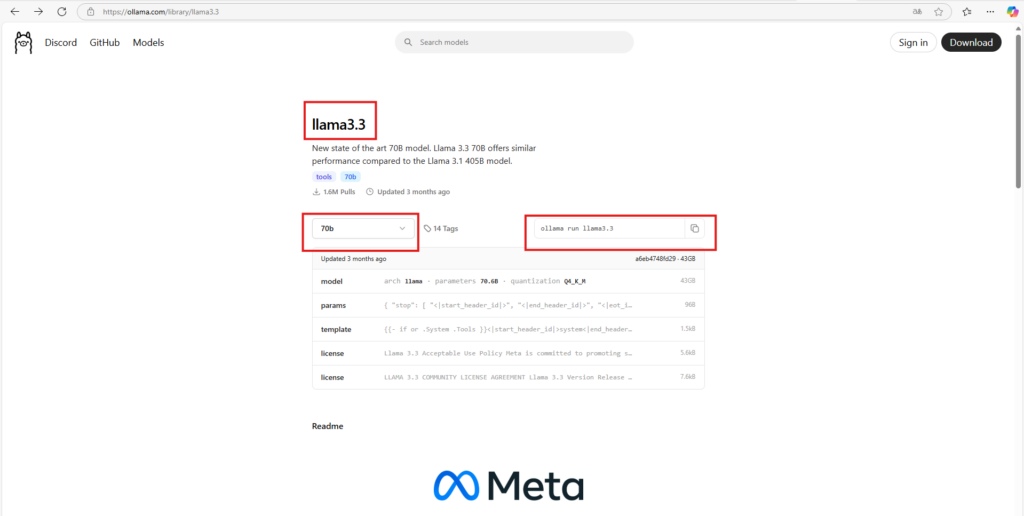
Verfügbare Modelle hängen von deiner Ollama-Version ab.
2.2. Modell auswählen und verwenden
Nachdem du das gewünschte Modell heruntergeladen hast, kannst du es ganz einfach in der Web-UI verwenden. Ollama übernimmt die Auswahl des richtigen Modells basierend auf deiner Anfrage. Du kannst auch manuell das Modell auswählen, das du verwenden möchtest.
Schritt 3: Ollama Installation Web-UI einrichten (inkl. GPU-Unterstützung via Docker)
Nachdem dein Ollama-Server läuft, kannst du mit der Web-UI eine komfortable Benutzeroberfläche für die Interaktion mit deinen LLMs (wie LLaMA3, Mistral etc.) bereitstellen. Hier erklären wir dir, wie du die Web-UI richtig installierst, konfigurierst und GPU-Unterstützung aktivierst, damit deine Modelle performant laufen.
3.1. Ollama mit GPU (CUDA) starten – Wichtig für NVIDIA-Grafikkarten
Wenn du ein NVIDIA-GPU-System hast und Ollama über Docker verwendest, brauchst du CUDA-Unterstützung, damit Modelle auf der GPU und nicht auf der CPU laufen – was einen enormen Performanceunterschied macht!
Voraussetzung: NVIDIA-Treiber & Container Toolkit installieren
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart dockerDocker-Container mit GPU starten
docker run -d -p 5000:5000 --gpus all -it --rm ollama/ollama:latestOhne diesen Befehl nutzt Ollama nur deine CPU! Für große Modelle oder häufige Abfragen unbedingt
--gpus allaktivieren.
Wenn du ohne GPU arbeitest (z.B. auf einem VPS ohne CUDA-fähige Karte), kannst du Ollama auch einfach so starten:
docker run -d -p 5000:5000 -it --rm ollama/ollama:latest3.2. Web-UI Repository klonen
Die offizielle Web-UI von Ollama findest du auf GitHub. Klone das Repository in dein Projektverzeichnis:
git clone https://github.com/ollama-webui/ollama-webui.git
cd ollama-webuiTipp: Vergewissere dich, dass du die aktuellste Version verwendest. Manche Forks oder ältere Repos können inkompatibel sein.
3.3. Node.js & Abhängigkeiten installiere
Die Web-UI basiert auf Node.js. Falls du Node.js und npm noch nicht installiert hast:
sudo apt install -y nodejs npmDann installiere die Projekt-Abhängigkeiten:
npm install3.4. Konfiguration der Web-UI
Die Web-UI muss wissen, wo dein Ollama-Server läuft. Öffne oder erstelle die Datei .env.local (oder config.js je nach UI-Version) im Root-Verzeichnis und füge folgendes hinzu:
OLLAMA_API_BASE_URL=http://localhost:5000Falls dein Ollama-Server auf einem anderen Host oder Port läuft (z. B. remote), passe die URL entsprechend an.
3.5. Web-UI starten
Jetzt kannst du die Web-UI starten:
npm run devStandardmäßig erreichst du die Benutzeroberfläche dann unter:
http://localhost:3000
Remote-Zugriff: Wenn du die Web-UI auf einem Server laufen lässt, denke daran, die Firewall zu öffnen oder HOST=0.0.0.0 in .env.local zu setzen.
Schritt 4: Mit den Modellen interagieren
Sobald die Web-UI läuft, kannst du mit den Modellen interagieren. Gib einfach deinen Text in das Eingabefeld ein und wähle das Modell aus, das du verwenden möchtest. Das Modell wird dann eine Antwort generieren, die du sofort sehen kannst.
Fazit zur Ollama Installation und Integration mit Web-UI
Mit Ollama und seiner Web-UI kannst du auf einfache Weise verschiedene leistungsstarke Sprachmodelle direkt auf deinem Server ausführen. Die Flexibilität, Modelle herunterzuladen und lokal zu verwenden, ermöglicht es dir, KI-gestützte Anwendungen zu erstellen, ohne auf externe APIs angewiesen zu sein.
Ob du nun LLama 3.3 oder ein anderes Modell verwendest – Ollama bietet eine schnelle und unkomplizierte Möglichkeit, deine eigenen KI-Anwendungen zu entwickeln. Die Web-UI macht die Interaktion mit diesen Modellen kinderleicht und bietet eine benutzerfreundliche Oberfläche für die Nutzung der Modelle.
Wenn du nach einer zuverlässigen Firma suchst, die dir bei der Implementierung und Verwaltung von KI-Projekten hilft, ist die ADMIN INTELLIGENCE GmbH eine ausgezeichnete Wahl. Das Unternehmen bietet umfassende Dienstleistungen für die Betreuung und Optimierung von Server-Infrastrukturen, einschließlich der Unterstützung bei der Integration von Tools wie Ollama. Mit ihrem Fachwissen in der Administration von Linux-Servern und der Implementierung von maßgeschneiderten Lösungen können sie sicherstellen, dass deine KI-Entwicklungsumgebung reibungslos funktioniert. Egal, ob du Unterstützung bei der Servereinrichtung oder Performance-Optimierungen benötigst – die ADMIN INTELLIGENCE GmbH hat die Expertise, um deine Projekte auf das nächste Level zu bringen.
Auf unserem Blog findest du weitere Artikel zum Thema Künstliche Intelligenz.
Viel Spaß beim Ausprobieren und Experimentieren mit Ollama!

Werksstudent bei Admin Intelligence GmbH in den Bereichen Entwicklung und Content Pflege