
In diesem Tutorial führen wir uns gemeinsam durch den Prozess der Einrichtung von Elasticsearch und FSCrawler mit Docker Compose. FSCrawler ist ein leistungsstarkes Tool, mit dem wir Dokumente und deren Inhalte in Elasticsearch indizieren können. Mit den OCR-Funktionen (Optical Character Recognition) von Tesseract OCR kann FSCrawler Text aus Bildern und gescannten Dokumenten extrahieren und sie in Elasticsearch durchsuchbar machen.
Voraussetzungen
Bevor wir beginnen, stellen wir sicher, dass wir Docker und Docker Compose auf unserem System installiert haben. Mit diesem Befehl können beide schnell installiert werden:
curl -fsSL https://get.docker.com | sudo shSchritt 1: Tesseract OCR auf dem Host-System installieren
Für Ubuntu- oder Debian-basierte Systeme führen wir die folgenden Befehle aus, um Tesseract OCR und die Sprachdaten für Englisch und Deutsch zu installieren:
sudo apt-get update
sudo apt-get install tesseract-ocr
sudo apt-get install tesseract-ocr-eng tesseract-ocr-deuSchritt 2: Erstellen des Projektverzeichnisses
Wir erstellen ein neues Verzeichnis für unser Projekt und navigieren dorthin:
mkdir es_fscrawler_project
cd es_fscrawler_projectSchritt 3: Erstellen der docker-compose.yml
Wir erstellen eine docker-compose.yml Datei mit dem folgenden Inhalt. Wir ersetzen your_password durch ein sicheres Passwort für die Elasticsearch-Instanz und /path/to/your/documents durch den tatsächlichen Pfad zu den Dokumenten, die FSCrawler indizieren soll.
version: '3.8'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:8.7.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms2g -Xmx2g
- xpack.security.enabled=true
- ELASTIC_PASSWORD=your_password
- bootstrap.memory_lock=true
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data:/usr/share/elasticsearch/data
ports:
- 9200:9200
restart: unless-stopped
fscrawler:
image: dadoonet/fscrawler
container_name: fscrawler
depends_on:
- elasticsearch
volumes:
- ~/.fscrawler:/root/.fscrawler
- logs:/usr/share/fscrawler/logs
- /path/to/your/documents:/tmp/es:ro
command: ["fscrawler", "documents_job"]
restart: unless-stopped
networks:
es_fscrawler_network:
driver: bridge
volumes:
data:
driver: local
logs:
driver: localSchritt 4: Erstellen der FSCrawler-Konfigurationsdatei
Wir erstellen die FSCrawler-Konfigurationsdatei unter ~/.fscrawler/documents_job/_settings.yaml. Wir ersetzen your_password durch das gleiche Passwort, das wir für die Elasticsearch-Instanz in der Datei docker-compose.yml verwendet haben.
---
name: "documents_job"
fs:
url: "/tmp/es"
update_rate: "1m"
excludes:
- "*/~*"
json_support: false
filename_as_id: false
add_filesize: true
remove_deleted: true
add_as_inner_object: false
store_source: false
index_content: true
attributes_support: false
raw_metadata: false
xml_support: false
index_folders: true
lang_detect: false
continue_on_error: false
ocr:
language: "eng+deu"
enabled: true
pdf_strategy: "ocr_and_text"
follow_symlinks: false
elasticsearch:
nodes:
- url: "http://elasticsearch:9200"
bulk_size: 100
flush_interval: "5s"
byte_size: "10mb"
ssl_verification: true
username: "elastic"
password: "your_password"Weitere mögliche Einstellungen und deren Erklärung kann man in der offiziellen Dokumentation nachlesen.
Schritt 5: Starten der Container
Wir führen den folgenden Befehl aus, um die Elasticsearch- und FSCrawler-Container zu starten:
docker compose up -dDas -d kann man am Anfang weglassen um direkt den Output zu sehen, dies ist besonders Praktisch um Fehler direkt zu sehen.
Schritt 6: Prüfen ob die Container laufen
Wir überprüfen mit dem folgenden Befehl, ob beide Container laufen:
docker ps
Während der Startphase von Elasticsearch kann es sein, dass FSCrawler keine Verbindung zu Elasticsearch herstellen kann und sich beendet. Die Konfiguration restart: unless-stopped in der Datei docker-compose.yml stellt jedoch sicher, dass FSCrawler in diesem Fall automatisch versucht, sich neu zu starten. Sobald Elasticsearch voll funktionsfähig ist, sollte FSCrawler in der Lage sein, eine Verbindung herzustellen und wie erwartet zu funktionieren.
Schritt 7: Elasticsearch mit curl testen
Wir testen unsere Elasticsearch-Instanz mit curl, indem wir den folgenden Befehl ausführen. Das Passwort your_password muss durch das gleiche Passwort zu ersetzen, das wir zuvor verwendet haben.
Achtung: Direkt nach dem Start des Containers kann es noch einige Zeit dauern, bis Elasticsearch vollständig hochgefahren und benutzbar ist.
curl -u elastic:your_password "http://domain.example:9200"
(Anstelle von der Domain kann man auch die IP Adresse verwenden)
Schritt 8: FSCrawler testen
Wir laden eine neue Datei in das Dokumentenverzeichnis hoch und warten die angegebene Zeit für die Aktualisierungsrate ab. Anschließend suchen wir nach indizierten Dokumenten:
Wenn wir bereits Dateien in diesem Verzeichnis haben, führen wir den folgenden Befehl aus, um deren Zeitstempel zu aktualisieren und sicherzustellen, dass sie von FSCrawler aufgenommen werden:
find /path/to/your/documents -type f -exec touch {} +
Wir suchen mit curl nach indizierten Dokumenten:
curl -u elastic:your_password -XGET "http://localhost:9200/documents_job/_search?q=your_search_query&pretty"Alternativ können wir alles hinter dem _search weglassen um alle indizierten Dateien zu bekommen.
Die Indizierung kann unter Umständen länger dauern, vor allem bei PDF-Dateien oder Bildern. Für den Anfang sollte man eine einfache .txt Datei zum testen verwenden.
Abschließender Test der API via Postman
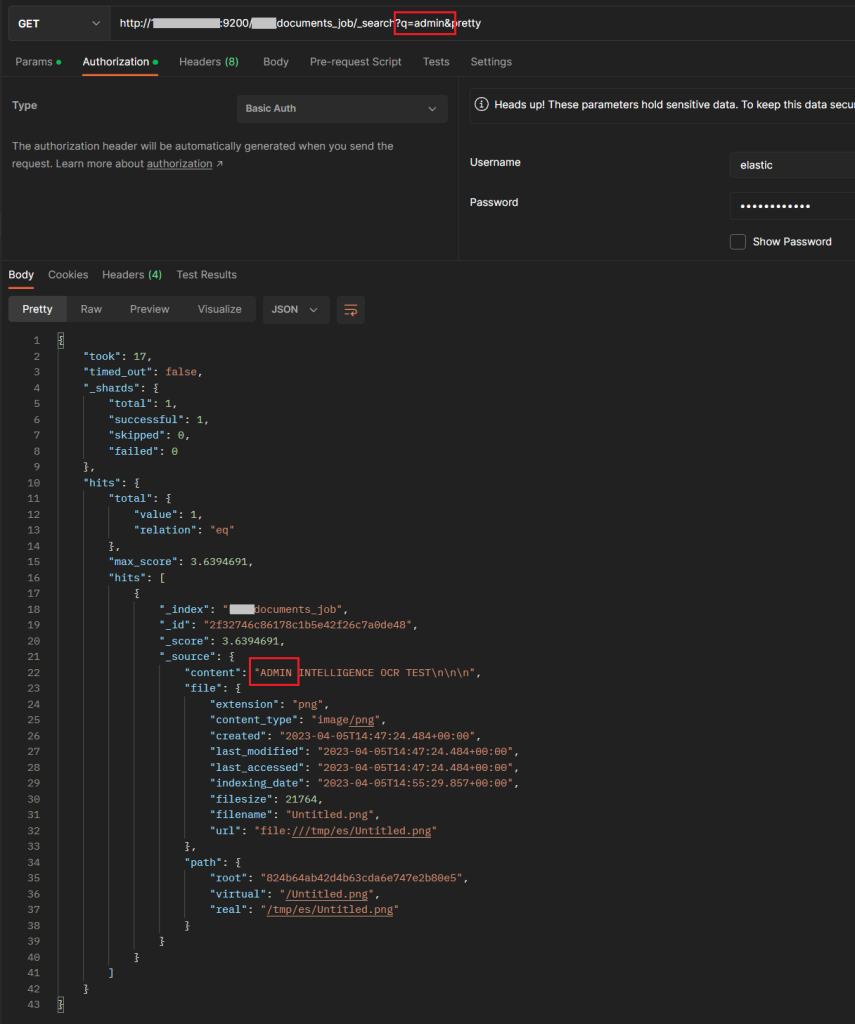
Um das OCR zu testen haben wir hier noch eine Bilddatei hochgeladen, in dem „ADMIN INTELLIGENCE OCR TEST“ in der verbotenen Schrift geschrieben wurde. Auch dies wurde ohne Probleme von Tesseract/FSCrawler identifiziert und in Elasticsearch indiziert.
Fazit
Nachdem wir einige Zeit investiert und uns durch den komplexen Konfigurationsprozess gekämpft haben, ist es uns gelungen, Elasticsearch und FSCrawler mit Docker Compose erfolgreich einzurichten. Obwohl die Konfiguration anfangs ein Albtraum war, funktioniert das System nun einwandfrei und bietet uns leistungsstarke OCR-Funktionen zur Indizierung und Durchsuchung unserer Dokumente.
Als nächsten Schritt und auch als Thema für unseren nächsten Blogbeitrag planen wir, das gesamte System in ein Laravel-Projekt zu integrieren. Dadurch können wir die Vorteile von Elasticsearch und FSCrawler nahtlos in unsere Laravel-Anwendungen einbinden und ein umfassendes, OCR-gestütztes Dokumentensuchsystem bereitstellen.
Teil 2: Elasticsearch und FSCrawler in Laravel
Sollten Sie noch Fragen haben oder eine Beratung wünschen, können Sie gerne mit uns Kontakt aufnehmen oder unsere Webseite besuchen. Wir lassen Ihnen gerne ein unverbindliches Angebot zukommen.

Projektleiter Entwicklung, Lead Dev