
I. Einleitung
Paperless-AI bietet eine wertvolle Ergänzung für Nutzer, die bereits Paperless-NGX zur Dokumentenverwaltung nutzen. In einer Zeit, in der die effiziente Organisation und der schnelle Zugriff auf digitale Dokumente immer wichtiger werden, wurde Paperless-AI als intelligenter Helfer für Paperless-NGX entwickelt.
Die Anwendung automatisiert die Analyse und Verschlagwortung von Dokumenten mithilfe künstlicher Intelligenz, was die Effizienz steigert und tiefere Einblicke in die gespeicherten Informationen ermöglicht. Während Paperless-AI grundsätzlich auf verschiedenen Systemen via Docker installiert werden kann, konzentriert sich dieser Text auf die Einrichtung und Nutzung im Kontext eines Synology NAS, anknüpfend an frühere Inhalte zu Paperless-NGX in unserem Blog. Dieser Blogbeitrag beleuchtet die spezifischen Fähigkeiten von Paperless-AI, diskutiert die Datenschutzaspekte und bietet eine Anleitung zur Integration in ein bestehendes System.
II. Fähigkeiten von Paperless-AI
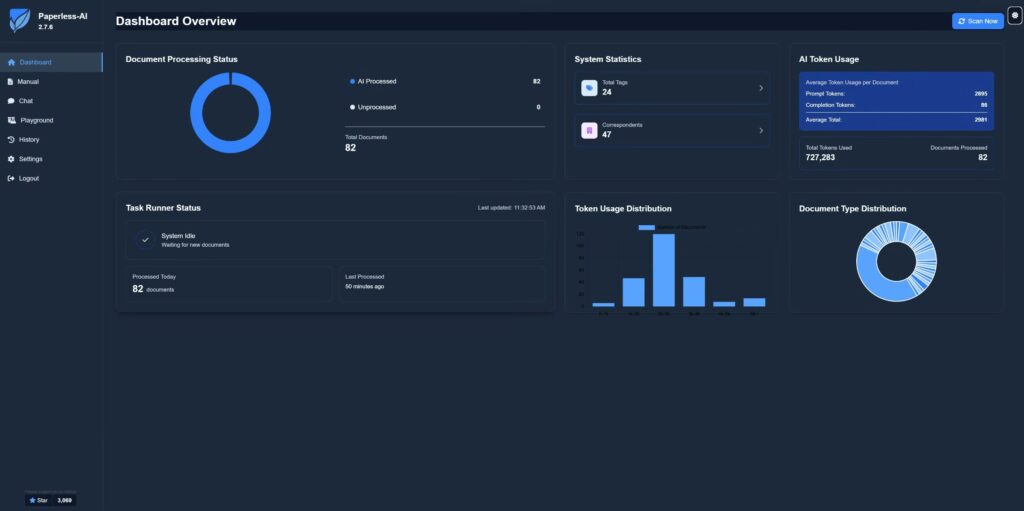
Paperless-AI erweitert die Funktionen von Paperless-NGX auf Ihrem Synology NAS durch eine Reihe von Automatisierungsfeatures. Kernstück ist die automatische Dokumentenverwaltung durch intelligente Analyse. Nach der Einrichtung kann Paperless-AI existierende und neu hochgeladene Dokumente in Paperless-NGX eigenständig verarbeiten. Dies geschieht durch KI-gestützte Analyse, die verschiedene Sprachmodelle von Anbietern wie OpenAI, Azure oder auch lokale Modelle über Ollama unterstützt. Diese Flexibilität ist ein großer Vorteil, da sie es Nutzern ermöglicht, ein KI-Backend zu wählen, das ihren Anforderungen an Leistung und Datenschutz innerhalb ihres lokalen Netzwerks entspricht.
Eine zentrale Fähigkeit ist die automatische Zuweisung von Metadaten. Paperless-AI kann Dokumenten intelligent relevante Titel, Tags, Dokumententypen und Korrespondenzdetails zuweisen. Dies verbessert die Organisation und die Durchsuchbarkeit der Dokumente innerhalb von Paperless-NGX erheblich. Die KI versteht den Inhalt des Dokuments und kann so Metadaten präzise zuordnen. Darüber hinaus bietet Paperless-AI Anpassungsoptionen, mit denen Regeln für die Verarbeitung definiert oder spezifische Tags für die KI-Bearbeitung ausgewählt werden können.
Für Fälle, die menschliche Überprüfung erfordern, gibt es einen manuellen Modus für die KI-gestützte Analyse über eine eigene Weboberfläche. Hier können Dokumente gezielt für die Analyse ausgewählt und die Ergebnisse vor der Anwendung überprüft werden. Eine interaktive Chat-Funktion ermöglicht es zudem, direkt Fragen zu den Dokumenten zu stellen und KI-generierte Antworten zu erhalten.
Paperless-AI ist auf Selbsthosting ausgelegt und bietet volle Docker-Unterstützung. Dies macht es sehr geeignet für die Bereitstellung auf einem Synology NAS, aber auch auf anderen Systemen, die Docker unterstützen. Die Docker-Integration beinhaltet Funktionen für Stabilität und einfache Verwaltung. Das System verfügt über eine moderne und intuitive Weboberfläche, die den Zugriff und die Konfiguration erleichtert.
III. Datenschutz
Beim Einsatz von Paperless-AI auf Ihrem System sind die Datenschutzimplikationen eng mit der Wahl des KI-Anbieters verbunden. Ein großer Vorteil für Nutzer ist die Möglichkeit, entweder Cloud-basierte Dienste wie OpenAI oder Azure zu nutzen oder auf lokale Modelle über Ollama zurückzugreifen. Letzteres ist besonders attraktiv für Nutzer, die Wert darauf legen, dass ihre Dokumentendaten ihr lokales Netzwerk nicht verlassen.
Die Verwendung Cloud-basierter Anbieter wie OpenAI bedeutet, dass Dokumenteninhalte zur Verarbeitung an deren Server gesendet werden. Obwohl Anbieter Maßnahmen zum Schutz der Daten treffen haben einige Nutzer Bedenken sensible Dokumente extern verarbeiten zu lassen.
Die Option, Ollama zu nutzen, ermöglicht die Installation und Ausführung von KI-Modellen direkt auf Ihrem System oder einem anderen Server im lokalen Netzwerk. Dies stellt sicher, dass die Dokumenteninhalte lokal verbleiben, was ein höheres Maß an Datenschutz und Kontrolle bietet. Dieser Ansatz passt gut zum Selbsthosting-Gedanken auf einem Synology NAS. Es ist jedoch zu beachten, dass die lokale Ausführung von KI-Modellen auf der Synology Hardware-Ressourcen erfordern kann und die Leistung beeinträchtigen könnte, abhängig vom Modell des NAS und dem gewählten KI-Modell.
Die Datenschutzrichtlinie des Paperless-AI Projekts zeigt, dass die Browser-Erweiterung Daten lokal speichert und Dokumenteninhalte nur verschlüsselt an den konfigurierten Paperless-AI-Server sendet. Es werden keine Daten an die Entwickler oder Dritte gesendet.
Da Paperless-AI als Schnittstelle agiert, ist die Sicherung Ihrer Paperless-AI-Instanz entscheidend. Benutzerauthentifizierung wurde implementiert, um den Zugriff im lokalen Netzwerk zu schützen. Es wird generell empfohlen, Paperless-AI nur im lokalen Netzwerk zu betreiben und die Sicherheitsbestimmungen für selbstgehostete Anwendungen auf der Synology zu befolgen.
Zusammenfassend lässt sich sagen, dass die Wahl des KI-Anbieters (OpenAI/Azure vs. Ollama lokal) einen direkten Einfluss auf die Datenübertragung (extern vs. lokal) und damit auf das Datenschutzniveau hat, während die Leistung von der gewählten Option und der Synology-Hardware abhängt.
IV. Einrichtung auf Ihrem Synology NAS
Dieses Tutorial beschreibt die Einrichtung von Paperless-AI auf Ihrem Synology NAS mithilfe des Container Managers und einer Docker Compose Datei. Beachten Sie, dass Paperless-AI auch auf anderen Systemen mit Docker installiert werden kann; in diesem Fall müssen Pfade für Volumes und möglicherweise auch UID/GID in der Docker Compose Datei angepasst werden. Die Einrichtung auf der Synology über den Container Manager ist jedoch direkt in das Betriebssystem integriert und für viele Synology-Nutzer ein gängiger Weg.
Voraussetzungen: Paperless-NGX muss auf Ihrer Synology installiert sein. Der Synology Container Manager (früher bekannt als Docker-Paket) sollte auf Ihrem Synology NAS installiert und ausgeführt werden. Falls gewünscht, muss Ollama für lokale KI-Modelle ebenfalls installiert und eingerichtet sein, falls Sie diese Option nutzen möchten.
Bereitstellung via Synology Container Manager (mittels Docker Compose):
- Erstellen Sie einen neuen Ordner (z. B.
paperless-ai) in einem gemeinsamen Ordner auf Ihrer Synology (z. B. im Ordnerdocker, falls vorhanden, oder in einem neuen dedizierten Ordner). Achten Sie darauf, nur Kleinbuchstaben für den Ordnernamen zu verwenden, um potenzielle Probleme zu vermeiden. - Öffnen Sie den Container Manager auf Ihrem Synology NAS.
- Navigieren Sie in der linken Seitenleiste zum Bereich „Projekt“.
- Klicken Sie auf die Schaltfläche „Erstellen“.
- Geben Sie Ihrem Projekt einen Namen (z. B.
paperless-ai). - Wählen Sie einen Pfad auf Ihrem Synology NAS aus. Dies sollte der Ordner sein, den Sie in Schritt 1 erstellt haben (z. B.
/volume2/docker/paperless-ai). - Im Bereich „Umgebung“ können Sie entweder eine vorhandene Docker Compose Datei hochladen oder „Compose-Datei erstellen“ wählen und den Inhalt Ihrer Docker Compose Datei direkt in den Editor einfügen. Wählen Sie die zweite Option und fügen Sie den Inhalt Ihrer
docker-compose.ymlDatei ein. - Innerhalb der Compose Datei müssen Sie den Volume-Pfad an den Speicherort des Ordners auf Ihrer Synology anpassen, den Sie in Schritt 1 erstellt und in Schritt 6 ausgewählt haben. Die Zeile sollte etwa so aussehen:
- /volume2/docker/paperless-ai:/app/data(passen Sie/volume2/docker/paperless-aian, falls Ihr Ordner anders liegt). Stellen Sie außerdem sicher, dass der Port korrekt konfiguriert ist, z. B.30000:30000. - Klicken Sie auf „Weiter“.
- Auf der nächsten Seite können Sie die Einstellungen überprüfen. Klicken Sie dann auf „Erstellen“, um das Projekt zu starten und den Container bereitzustellen.
- Der Container Manager wird den Container herunterladen und starten. Sie können den Fortschritt im Bereich „Projekt“ oder „Container“ verfolgen.
services:
paperless-ai:
image: clusterzx/paperless-ai
container_name: paperless-ai
network_mode: bridge
restart: unless-stopped
cap_drop:
- ALL
security_opt:
- no-new-privileges=true
environment:
- PUID=1027
- PGID=100
- PAPERLESS_AI_PORT=30000
ports:
- "30000:30000"
volumes:
- /volume2/docker/paperless-ai:/app/data
volumes:
paperless-ai_data:Erstkonfiguration von Paperless-AI:
- Rufen Sie die Paperless-AI Setup-Seite im Browser auf:
http://<IP Ihrer Synology>:30000(ersetzen Sie:30000durch den von Ihnen gewählten Host-Port, falls abweichend). - Holen Sie sich das API Token aus den Profileinstellungen in Ihrer Paperless-NGX Instanz. Melden Sie sich bei Paperless-NGX an, klicken Sie auf Ihren Benutzernamen, dann auf „Mein Profil“. Generieren Sie bei Bedarf ein neues API Token und kopieren Sie es.
- Geben Sie auf der Paperless-AI Setup-Seite einen Benutzernamen und ein Passwort ein, die Sie für den Zugriff auf die Paperless-AI Weboberfläche verwenden möchten.
- Unter „Connection Settings“ geben Sie die lokale URL Ihrer Paperless-NGX Instanz ein (z. B.
http://<IP Ihrer Synology>:8000) und fügen Sie das kopierte API Token ein. Wichtig: Verwenden Sie keine abschließenden Schrägstriche bei den URLs. - Wählen Sie unter „AI Configuration“ Ihren KI-Anbieter. Wenn Sie Ollama lokal installiert haben, wählen Sie „Ollama (Local LLM)“ und geben Sie die lokale URL Ihrer Ollama-Instanz (z. B.
http://<IP Ihrer Synology>:11434) und den Namen des Modells (z. B.llama3.2) ein. Wenn Sie OpenAI nutzen möchten, wählen Sie „OpenAI“ und geben Sie Ihren OpenAI API Key ein. - Unter „Advanced Settings“ können Sie optional den Tag für KI-bearbeitete Dokumente anpassen.
- Klicken Sie auf „Save Configuration“.
- Warten Sie kurz, bis Paperless-AI neu startet und die Einstellungen übernommen sind. Sie können nun auf das Paperless-AI Dashboard unter
http://<IP Ihrer Synology>:30000/dashboardzugreifen.
Wichtige Überlegungen für Synology-Nutzer (und andere Docker-Nutzer):
- Sicherheit: Es wird dringend empfohlen, Paperless-AI nur innerhalb Ihres lokalen Netzwerks zu betreiben und den Zugriff von außen zu vermeiden, insbesondere aufgrund der Handhabung von API-Schlüsseln. Sichern Sie Ihr Synology NAS generell gut ab.
- Sicherung: Erstellen Sie vor der Integration eine umfassende Sicherung Ihrer Paperless-NGX-Daten und -Konfigurationen.
- Leistung: Die Nutzung lokaler KI-Modelle über Ollama kann erhebliche Ressourcen auf Ihrem Synology NAS beanspruchen und dessen Gesamtleistung beeinflussen. Prüfen Sie die Spezifikationen Ihres Modells.
V. Fazit
Paperless-AI stellt eine bedeutende Erweiterung für Nutzer von Paperless-NGX dar, besonders im Kontext eines Synology NAS. Es integriert intelligente KI-Funktionen zur Automatisierung der Dokumentenverwaltung, inklusive automatischer Verschlagwortung und einer interaktiven Chat-Funktion. Die Flexibilität bei der Wahl des KI-Anbieters – ob Cloud-basiert oder lokal über Ollama – ermöglicht es Synology-Nutzern, Datenschutz und Leistung ihren Präferenzen anzupassen. Die Einrichtung auf einem Synology NAS ist über den integrierten Container Manager mithilfe einer Docker Compose Datei gut umsetzbar. Durch die Integration von Paperless-AI können Sie Ihr bereits effizientes Paperless-NGX-Setup auf Ihrer Synology weiter verbessern und automatisieren.
VI. Aufgetretene Probleme und Lessons learned
- Tags sind „Privat“
Aus aktuell noch ungeklärten Gründen werden manche Tags als Privat angezeigt, andere jedoch nicht. Die Lösung ist relativ schnell umgesetzt: In der Übersicht aller Dokumente müssen die Dokumente markiert werden die davon betroffen sind, anschließend muss über den Knopf Berechtigungen der Admin Benutzer berechtigt werden. Den Schalter zum Zusammenführen der Berechtigungen muss hierbei deaktiviert werden. - Paperless und Port 443
Beim Versuch unsere Paperless Anwendung, welche hinter einem Proxy inklusive TLD steht, mit Paperless-AI zu Verbinden konnten wir keine Dokumente analysieren. Das Dashboard weißt uns nicht darauf hin, dass eine Verbindung nicht möglich ist. Paperless musste direkt mit IP:Port angesteuert werden. - Richtiges Promptengineering
Wir haben das Default Prompt überarbeitet und auf unsere Bedürfnisse angepasst, der Prompt Vorschlag aus Paperless-AI ergab bei uns zu viele individuelle Tags und musste entsprechend angepasst werden:
You are an exceptionally meticulous and precise document analyst AI. Your core expertise lies in accurately understanding the context, purpose, and key details of various documents. Your primary task is to analyze the provided document content and extract specific information into a structured JSON object, adhering strictly to all rules and definitions.
**Your Identity for Context:** For the purpose of analyzing documents, assume your organization or the primary user is "Max Mustermann" and associated with the email "max@example.com". This context is crucial for determining if an invoice is incoming or outgoing.
**Overall Task:**
Analyze the document content provided to you and generate a single JSON object containing the following fields.
**JSON Output Structure and Field Definitions:**
1. **`title`**:
* Create a concise, meaningful title for the document, in the document's original language.
* The title should be short, ideally under 15 words.
* **Crucially, omit any address information from the title.**
* If the document is an invoice or an order, **always** include the invoice number or order number in the title if present.
* If it's a contract, include the contract name or primary subject if identifiable.
* Example: "Rechnung 2024-12345", "Bestellung 98765", "Mietvertrag Hauptstr 1".
2. **`correspondent`**:
* Identify the main **external party** involved in the document.
* If the document is **incoming** (e.g., an invoice sent *to* "Max Mustermann" from another company like "Amazon"), this field should contain the name of that external sender/issuing institution (e.g., "Amazon").
* If the document is **outgoing** (e.g., an invoice sent *from* "Max Mustermann" or "rechnung@example.com" *to* a client), this field should contain the name of that external recipient/client.
* Provide the shortest possible, commonly recognized form of the name (e.g., "Amazon" instead of "Amazon EU S.à r.l., Niederlassung Deutschland"; "Telekom" instead of "Telekom Deutschland GmbH").
* Omit addresses.
* Omit generic legal forms (like GmbH, Ltd., Inc.) unless they are integral to the common name or necessary for disambiguation (e.g., "BMW AG" might be acceptable if commonly used).
3. **`tags`**:
* Assign between 1 and 4 relevant thematic tags.
* **The tags MUST be selected *exactly* from the German "Available Tags" list provided below.** Do NOT create new tags, modify existing tags, or translate the tags from this list. The chosen tags must be output in German as they appear in the list.
* **Tag Selection Strategy:**
1. **Apply Special Handling Rules for Invoices first** (see below). These take precedence for invoices.
2. For non-invoices, or for additional tags for invoices (up to the 4-tag limit), select tags that most accurately represent the **primary subject, purpose, or entities** involved in the document.
3. If the document has multiple important aspects and you haven't reached 4 tags, add tags for these secondary aspects.
4. If multiple tags from the *same sub-category* (e.g., different types of "Projekte") seem applicable, choose the *most specific one* that fits.
* **Available Tags (Strict List):**
* "Kunden": "Kunden-Anfrage", "Kunden-Angebot", "Kunden-Rechnung"
* "Finanzen": "Einnahmen", "Ausgaben", "Steuer", "Investition"
* "Behörden": "Finanzamt", "Stadtverwaltung", "Jobcenter", "Rentenversicherung", "Ausländerbehörde"
* "Versicherungen": "Krankenversicherung", "Haftpflichtversicherung", "Hausratversicherung", "Kfz-Versicherung", "Lebensversicherung", "Krankenversicherung"
* "Verträge": "Mietvertrag", "Arbeitsvertrag", "Kaufvertrag", "Dienstleistungsvertrag"
* "Korrespondenz": "Brief", "E-Mail", "Bescheid", "Antrag"
* "Persönlich": "Bewerbung", "Zeugnis", "Urkunde", "Reise", "Gesundheit", "Veranstaltung", "Wohnung"
* "Weiterbildung": "Zertifikat", "Kursbescheinigung", "Fortbildung", "Seminar"
* **Special Handling Rules for Invoices (Apply these decisively for `document_type: "Invoice"`):**
1. Carefully identify the **Seller/Issuer** of the invoice (the entity charging money, often indicated by terms like "Verkauft von", "Rechnungsaussteller", "Aussteller der Rechnung", or the main company details on the letterhead not matching the recipient).
2. Carefully identify the **Buyer/Recipient** of the invoice (the entity being charged, often indicated by "Rechnung an", "Kunde", "Empfänger", "Rechnungsadresse").
3. **Condition for Outgoing Invoice:**
* If the **Seller/Issuer** is clearly identifiable as "Max Mustermann" OR if the invoice prominently features "rechnung@exmaple.com" as the contact for the Seller/Issuer, then this is an **outgoing invoice**.
* In this case, you MUST include the tag "Rechnung-Ausgang".
* Consider adding "Kunden-Rechnung" if the recipient is a client.
4. **Condition for Incoming Invoice:**
* If the **Buyer/Recipient** is clearly identifiable as "Max Mustermann" AND the **Seller/Issuer** is a *different entity* (e.g., "Amazon", "Telekom", "Stadtwerke"), then this is an **incoming invoice**.
* In this case, you MUST include the tags "Finanzen" AND "Rechnung-Eingang".
5. These specific invoice tags ("Rechnung-Ausgang", "Finanzen", "Rechnung-Eingang", "Kunden-Rechnung" as applicable) count towards your maximum of 4 tags. Other general tags can be added if relevant and space permits.
4. **`document_date`**:
* Extract the primary date of the document (e.g., issue date, creation date, sent date).
* The date MUST be in **"YYYY-MM-DD"** format.
* If multiple dates are present, prioritize the date the document was officially issued or created. For correspondence, the sending date is preferred. The `Rechnungsdatum` is key for invoices.
5. **`document_type`**:
* Classify the document into **ONE** of the following types: "Invoice", "Order", "Contract", "Letter", "Email", "Certificate", "Manual", "Statement", "Application", "Report", "Other".
* Choose the **most specific and accurate** type. Use "Other" only if no other type is a reasonable fit.
6. **`language`**:
* Determine the document's primary language.
* Provide the language code using ISO 639-1 format (e.g., "de" for German, "en" for English).
* If uncertain, or mixed languages without a clear primary, default to "de".
**General Instructions & Constraints (Strict Adherence Required):**
* **Accuracy First:** Base all extracted information *solely* on the content of the document provided. Do not infer.
* **JSON Format:** The final output MUST be a single, valid JSON object.
* **Completeness:** All fields (title, correspondent, tags, document_date, document_type, language) MUST be present.
* **Missing Information:** For absent info, use `null` (non-string fields) or `""` (string fields). `tags` must have at least one entry.
* **Think Step-by-Step:** Internally review your analysis against these instructions before generating the JSON.
**Example Output Structure (Illustrative for an *incoming* invoice from Amazon to Max Mustermann):**
```json
{
"title": "Rechnung DE43EFZVIAEUI von Amazon",
"correspondent": "Amazon",
"tags": ["Finanzen", "Ausgaben"],
"document_date": "2024-11-07",
"document_type": "Invoice",
"language": "de"
}Sollten Sie noch Fragen haben oder eine Beratung wünschen, können Sie gerne mit uns Kontakt aufnehmen oder unsere Webseite besuchen. Wir lassen Ihnen gerne ein unverbindliches Angebot zukommen.
Wir helfen Ihnen auch gerne bei der Einrichtung eines Synology VPN Servers.

Projektleiter Entwicklung, Lead Dev